
何庭波 华为
摘要
六十年来,摩尔几何缩放驱动了半导体的进步。这一行业契约已不再成立:纯尺寸缩小的回报已趋平坦,前沿芯片设计预算超过十亿美元,最先进节点的每晶体管成本不再下降。本文提出一个继任缩放原则——τ缩放——以时间本身而非晶体管面积作为进步的首要度量,将单一特征时间常数τ作为跨越十二个数量级的统一优化目标,从皮秒级的晶体管开关到秒级的数据中心工作负载。文中展示了两个量产级验证。在移动SoC上,LogicFolding——一种将数字、模拟和存储电路分布在垂直堆叠有源层上的方法论——在固定器件节点上实现了55%的晶体管密度阶跃提升和41%的能效增益。在AI系统上,由存储语义Unified Bus互联架构、近封装Hi-ONE光学I/O和边缘到表面3D Folding组成的协同设计堆栈,预计到2035年实现超过100倍的硬件集成增长。更深层的主张是方法论层面的:τ缩放是自Dennard以来第一个在整个计算堆栈中建立共享优化目标的缩放原则。
引言
自1960年代中期以来,半导体行业以纳米为单位衡量进步。每十八个月,晶体管缩小,频率提升,每逻辑门成本下降。摩尔定律既是经验观察,也帮助建立了整个计算堆栈赖以构建的行业契约。这一行业契约已不再成立。在7纳米节点之后,几何缩放不再提供其历史红利。光刻工具正在接近图案化的物理极限,EUV折旧主导了晶圆成本,每晶体管价格曲线已趋平坦——在某些情况下甚至出现逆转。对于那些获取最先进光刻设备受限的组织,这一约束更早地变得具有约束力,且压力更为严峻。
因此,行业面临的核心问题已经改变。不再是"晶体管还能缩小多少?"而是"应该缩放什么,以什么为目标?"
过去六年,作者在华为半导体的团队在移动SoC、AI加速器、系统互联架构和封装领域对这一问题进行了硅片级的研究。结论是:答案不在于另一个节点,也不在于另一种晶体管架构,而在于改变首要优化目标本身。本文主张,未来十年电子系统演进应以时间缩放而非几何缩放为指导——即系统性地缩减跨越堆栈每一层的单一特征时间常数τ,从皮秒级的晶体管开关到秒级的数据中心工作负载响应。
τ缩放的论证在下文中既作为科学方法论也作为产业路线图展开,基于2020年5月至2026年5月间381颗量产芯片的经验教训。
1. 几何时代的终结
在其大部分历史中,半导体行业只有一个任务:让晶体管更小。Gordon Moore在1965年的观察——晶体管密度大约每两年翻一番——十年后由Robert Dennard的缩放理论加以补充,后者确立了电压和尺寸的等比缩小可以维持恒定电场。几何缩放和Dennard缩放共同在近五十年间带来了每瓦性能和每美元性能的指数级提升。
这一安排分两个阶段瓦解。大约2005年,Dennard缩放首先失效:电压不再与特征尺寸等比缩放,暗硅时代开始。几何缩放持续了更长时间,由FinFET以及随后的全环栅(GAA)器件架构所支撑。然而,在7纳米之后,纯尺寸缩放的回报已趋平坦。原因现已充分记录:速度饱和将本征延迟对沟道长度的依赖从二次方降为线性;局部互连的寄生电阻和电容日益主导标准单元延迟预算;掩模成本、EUV折旧和设计规则复杂性已将2纳米节点的前沿芯片设计预算推至超过十亿美元。
经济后果同样不可回避。先进节点的每晶体管成本已趋平坦,在最前沿甚至开始上升。支撑过去五十年的行业契约——每一代以更低成本获得更多晶体管——已不再成立。
对华为半导体而言,这一转变伴随着额外的约束:获取最先进光刻工具受到限制。假设另一个节点能解决问题已不再可行。六年前,几何路线图停滞,迫使我们面对一个更根本的问题——回顾来看,整个行业最终都将不得不面对这个问题。
2. 时间而非空间:摩尔时代的真正货币
就其对终端用户的本质效果而言,摩尔定律从来不是根本性地关于几何。更小的晶体管改善了系统性能,因为它们开关更快。更密集的互连改善了性能,因为信号穿越更短的距离。更高的集成度改善了性能,因为数据跨越更少的边界。每一代所交付的,本质上是时间的缩减——器件层面从皮秒到纳秒,芯片层面从纳秒到微秒,系统层面从微秒到秒。空间缩放仅仅是压缩时间的工具。
一旦认识到这一点,一个显而易见的重构便呈现出来。时间本身应被采纳为首要度量。特征时间常数τ可以在堆栈的每一层定义——晶体管、电路、芯片和系统——其缩减被视为统一的优化目标。几何缩放于是成为缩减τ的众多技术之一,而非唯一的技术。
这一原则被称为τ缩放,在此作为几何摩尔缩放的继任者、半导体演进的指导原则而提出。形式上,τ被视为一个分层构造,分解为:
τ = f(τtransistor, τcircuit, τchip, τsystem)
其中τtransistor、τcircuit、τchip和τsystem分别代表晶体管、电路、芯片和系统层的时间常数。每一层的τ由其下层的τ加上该层引入的组织和通信开销组合而成。τ的工作空间跨越大约十二个数量级的时间(皮秒到秒)和相当范围的空间(纳米到千米)。在每一层,都有不同的机制可用于缩减τ:
- 晶体管:本征开关延迟,通过迁移率增强、应变工程、高κ/金属栅极和GAA架构来解决,以及越来越多地通过缩减局部互连的寄生R和C来解决——后者现已超过本征渡越时间数倍。
- 电路:信号路径上的RC传播延迟,通过更低电阻率的导体、低κ介电质来解决,以及——最为关键地——通过垂直集成缩短线长来解决。
- 芯片:计算和存储器访问延迟,通过架构选择、流水线深度、存储层次和片上互联来解决。
- 系统:端到端消息和同步时间,通过互连拓扑、协议栈和互联架构设计来解决。
从这一分层公式中产生了一个有用的代际规则:
τ(n+1) = τn / α
其中缩放因子α是应用特定的而非通用的。迄今的量产经验表明,功耗受限的移动设备约为每年1.3倍,安全关键的自动驾驶系统约为每年1.5倍,AI工作负载高达每年10倍——在AI领域,吞吐量直接转化为经济价值。
使τ成为有用的首要度量而非现有度量的重新标记的原因在于:它是跨越整个堆栈的同一度量。频率、延迟、带宽和吞吐量在各自层面都受τ支配。工艺技术专家、电路设计师和系统架构师可以用相同的单位讨论同一个量。τ是使端到端堆栈协同优化成为可能的语言——而各层独立优化、时序作为残差出现的时代已经结束。
3. LogicFolding:移动SoC验证点
τ缩放的第一个量产级测试在移动领域进行。智能手机SoC是一个特殊案例:一颗芯片构成整个系统。多插槽并行不可用;没有千节点互联可以掩盖慢速链路。交付给用户的所有性能都来自单颗芯片,在几瓦功耗包络下,受手持形态因子约束的热限制。
2020年之后,当获取前沿节点受到限制时,核心问题变为:在节点固定的情况下,如何在单颗芯片上继续实现代际改进?
答案被称为LogicFolding。
定义。 LogicFolding是一种设计方法论,将数字、模拟和存储电路分布在垂直堆叠的有源层上,遵循时间缩放原则联合优化性能、功耗和面积。
数字电路分为组合逻辑——寄存器之间的布尔网络——和时序逻辑——保持状态的触发器。数字系统的性能上限由相邻触发器级之间的关键路径延迟决定,而关键路径延迟又由该路径上的互连RC和门数量主导。传统优化将门放置在平面上,通过上方的金属堆栈布线;线越长,寄生RC越大,关键路径越慢。
LogicFolding放弃了平面假设。关键路径门分布在两个(最终更多)垂直堆叠的有源层上,通过超细间距混合键合连接。从电路设计师的角度看,两层表现为单一连续的布局空间,单元跨越晶圆边界分布,如同它是一个额外的金属层。信号线变得显著更短,寄生RC急剧下降,时钟偏斜收紧,芯片在相同器件节点上以更高时钟频率运行。
为使LogicFolding实现这些增益,保持混合键合间距与顶层金属间距之间的齿轮比相对较低是有利的——实践中大致低于3,比值越低通常越好。以当前约720纳米的顶层金属间距计算,这意味着混合键合间距低于2微米——理想情况下齿轮比约为1,此时键合界面处的鸟笼布线开销实际上消失。实现这一间距,加上所需的对准精度(<0.5微米)、TSV缩放(CD和KOZ亚1.5微米,间距亚6微米)和良率(通过智能冗余接近100%),需要跨供应商和合作伙伴生态系统的多年工艺开发努力。
在麒麟2026上测量的结果是具体的:
- 晶体管密度在单代内从155阶跃提升至238 MTr/mm²(晶体管密度使用公式2/(CPP×cell height)计算;麒麟SoC设计的面积利用率为68%)——这一改进幅度此前需要三年的几何缩放。
- SoC性能核心能效提升41%,最大时钟频率提升近13%。
- 跨上下两层构建的高速全局片上网络数据通路将数据通路面积缩减55%,同时改善了供电稳定性。
- 硅后时钟偏斜调整方案独立贡献了超过5%的SoC性能。
- 在SRAM上——其访问速度、每比特能耗和面积强烈依赖于位线和字线长度——LogicFolding缩短了关键路径,降低了每比特能耗,并将工作频率提升超过40%。
- 在一个代表性处理核心上,双层折叠架构将时钟缓冲器数量减少超过50%,时钟偏斜减少25%,线长减少约30%。
这些增益在固定器件节点上实现,不是通过新的光刻步骤,而是通过逻辑在三维空间分布的拓扑重组。
麒麟2026中的LogicFolding实现是刻意保守的。混合键合间距达到1.5微米;TSV着陆仅在顶层金属下方推进一步;折叠仅选择性地应用于关键路径而非整个设计。即便如此,CPU性能核心频率今年回到3.1 GHz。
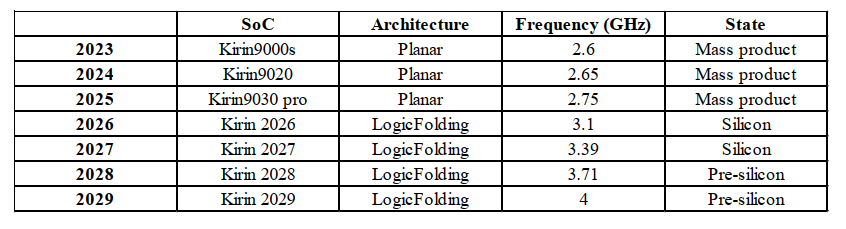
在未来十年,LogicFolding预计将从局部关键路径折叠演进到全规模多层折叠——每个封装三层、四层甚至更多有源层——由更低温度的混合键合(放宽跨层热预算)和TSV着陆从顶层金属向下迁移至M6(释放超过30%的高层布线资源)所使能。从2026年到2035年,晶体管密度预计将向400 MTr/mm²及以上发展。同时,LogicFolding使麒麟能够大幅提升CPU核心频率,为4 GHz及以上铺平道路(表1)。路线图是可行的,在成本方面也是经济可行的。
表1. 麒麟CPU性能核心工作频率趋势。
侧栏A — LogicFolding概览
- 混合键合间距:亚2微米(麒麟2026为1.5微米;目标齿轮比≈1)
- 对准精度:低于0.5微米
- TSV CD/KOZ:亚1.5微米;间距亚6微米;失效率<100 ppm;修复率99.9%
- 良率:通过智能冗余接近100%
- 晶体管密度:155→238 MTr/mm²单步提升
- 能效/频率增益(SoC性能核心):+41% / +13%
- SRAM工作频率:+40%以上
- 代表性核心的时钟缓冲器数量/时钟偏斜/线长:−50% / −25% / −30%
4. 从皮秒到微秒:AI数据中心中的τ缩放
一个自然的问题是:在毫瓦级智能手机领域开发的原则能否经受住向吉瓦级AI训练和推理领域的转化。AI工作负载占据τ频谱的另一端:不是单颗芯片,而是数百或数千颗芯片作为一台机器运行,过去十年间聚合计算量增长了约六个数量级。
答案是肯定的——前提是τ被视为系统级目标并应用于整个链条,而非仅在单个加速器内部。
两个事实塑造了τ论证的AI侧面。第一,AI系统持续增长——从一颗芯片到数十颗,到数百颗,越来越多地到数万颗。第二,现代AI系统的能量预算和材料预算由数据而非计算主导。大型AI集群中超过80%的能量被数据移动消耗;超过70%的系统成本分配给数据存储。含义是直接的:缩减数据在传输中花费的时间——芯片之间、机架之间和封装内部——至少与缩减计算花费的时间同等重要。
τ缩放在AI规模上通过三个协调层实例化:系统互联架构(Unified Bus)、近封装光学引擎(Hi-ONE)和封装本身的拓扑重组(3D Folding)。
4.1 Unified Bus——τ优先的系统互联架构
传统的多节点、多加速器架构通过多个堆叠协议移动数据:PCIe到主机,NVLink或专有互联在机箱内,以太网或InfiniBand在机箱间,以及软件栈远程内存访问在顶层。每一层都需要协议转换、额外的序列化、额外的DMA缓冲区和进一步的握手。每次转换都增加延迟、降低可靠性并产生额外成本。
Unified Bus(UB)用单一协议替代这一堆栈,该协议在机箱内和机箱间运行——一个完全对等的互联架构,在整个系统中原生暴露内存语义。数据移动被简化为无转换的、对等的内存语义层传输,以硬件管理的一致性取代软件栈消息传递。
测量的收益约为两个数量级:端到端远程访问延迟从TCP/IP类堆栈典型的数十微秒降至约100纳秒——沿主要通信轴约500倍的系统τ缩减。在机架规模上,这使系统渐近地接近单一的、互联一致的机器——内部称为System-as-One-Chip。
4.2 Hi-ONE——封装级光学I/O
一旦通信延迟被缩减,下一个瓶颈就会转移。在单个机架内增加芯片密度将功率密度和可靠性推至极限——也将电气SerDes推至极限。在每AI芯片400 Gb/s时,铜缆仍然是充分理解和可靠的。在每芯片多Tb/s时,铜变得物理上不可行:SerDes达到距离限制,布线变得过于笨重,面板安装变得不可行,热和供电裕量被耗尽。
华为半导体开发的方案是高密度光互连节点引擎Hi-ONE——一种近封装光学引擎,每模块提供8 Tb/s,在单条光链路上匹配AI芯片的UB带宽。它将所需的SerDes距离从约100厘米缩减到约5厘米,消除了笨重的布线,并将传输距离从不到一米扩展到100米——使分布式吉瓦级数据中心的高密度互连在物理上可实现。
Hi-ONE的设计哲学本身就是一个τ缩放论证。它不使用重型DSP来获得高信号保真度,而是采用线性方案——模拟均衡增强的驱动器和跨阻放大器——并允许UB协议容忍刻意放宽的误码率。这种协议层和物理层之间的跨层权衡降低了功耗、成本和集成复杂性,体现了τ优先方法论所奖励的跨层权衡。
4.3 N²对N困境,以及为什么3D Folding不可避免
AI加速器不会止步于2.5D扇出的最深层原因是几何性的,值得明确阐述,因为它决定了2030年后的路线图。
在传统的2.5D AI芯片中,逻辑芯片占据封装中心,HBM堆栈和SerDes排列在其边缘,电压调节器环绕封装。每个存储信号、每个互连信号和每安培供电电流都必须穿越芯片边缘才能到达内部的计算资源。如果芯片边长为N,则:
- 计算容量按N²缩放(面积),
- 但存储带宽、互连和供电——全部由沿边缘的2.5D扇出承载——仅按N缩放(周长)。
这些二次方和线性曲线之间不断扩大的差距构成了扇出困境,它解释了2.5D缩放的停滞,与底层逻辑节点多么激进无关。没有任何晶体管级改进能弥合拓扑缺陷。
3D Folding通过将边缘绑定的资源重新定位到表面来解决这一困境。供电(通过背面供电和集成电压调节器)、高速存储(通过混合键合到逻辑)和光学I/O(通过近封装Hi-ONE)全部从周边迁移到垂直表面——一旦位于表面上,它们就按N²缩放,匹配计算的二次方增长速度。封装不再是被存储和SerDes周边带环绕的逻辑芯片;它变成了一个垂直集成的堆栈,其中存储、互联、供电和逻辑全部一起缩放。
路线图将这一演进置于明确的时间线上。大约到2030年,AI加速器(昇腾SuperPoD系列——2025年的昇腾910C、2026年的昇腾950,以及随后的990)依赖成熟技术的组合:chiplet、2.5D扇出和通过微凸块及标准间距混合键合的3D堆叠。大约2030年,昇腾990将把LogicFolding引入AI加速器类别,从那时起3D Folding成为到2035年α的主要载体。沿这条路径,硬件集成预计到2035年增长超过100倍,τ缩减分布在堆栈的每一层而非集中在器件层面。
侧栏B — AI系统规模的τ
- UB远程访问延迟:约数十微秒→约100纳秒(约500倍τ缩减)
- Hi-ONE每模块带宽:8 Tb/s(匹配每芯片UB带宽)
- Hi-ONE SerDes距离:约100厘米→约5厘米;面板间距离:<1米→100米
- 扇出困境:计算∝N²,周边绑定的带宽/I/O/供电∝N
- 3D Folding:将带宽、光学I/O和供电从边缘重新定位到表面,恢复N²对等
- 2026→2035预计硬件集成增长:>100倍
5. 逻辑与存储:从解耦到再融合
τ缩放的一个含义值得单独讨论,因为其后果既是产业性的也是技术性的。
在8086时代,行业通过标准化存储总线刻意将处理器和存储解耦。这种解耦允许两个行业独立缩放:处理器性能沿摩尔曲线快速推进,而存储厂商在其旁边发展了一个庞大的独立市场。
AI时代正在逆转这种解耦。计算密度的持续扩展正在将存储带宽、延迟、功耗和封装推至极限。HBM、混合键合和3D堆叠SRAM是一个单一底层事实的症状:对于现代AI工作负载,数据移动与计算本身同等关键,逻辑和存储正再次被驱动进入紧密的物理集成。随着它们的融合,供应链中的影响力平衡正在向存储和封装厂商转移。
技术方向是明确的,但经济解决方案尚未确定。AI硬件时代的持久成功将归于那些能够在技术上融合逻辑和存储、并建立经济伙伴关系使两个行业长期共享融合收益的组织。这不仅是一个研究问题;它是行业在未来十年需要解决的结构性问题。通过使每一次分离的跨层成本可见,τ缩放确保这个问题不能被推迟。
6. 开放挑战
将τ缩放呈现为一个完成的系统是误导性的。若干实质性问题仍然开放,在此加以识别,既为突出正在进行的工作,也为邀请合作。
工具链和方法论。 当今的EDA是为面积、时序和功耗沿三个独立轴优化、系统τ作为残差出现的时代开发的。全规模LogicFolding要求工具链将多个堆叠芯片视为单一连续设计实体——以单元粒度而非模块粒度分割逻辑,在统一成本函数下跨全体积放置,并在跨芯片路径上执行时序收敛,其中垂直互连寄生参数、KOZ排除区和晶圆间工艺变异以传统2D训练工具无法充分处理的方式相互作用。初步的内部工具已开发并产生有用结果,方法论细节将在未来数月发表。一个τ原生的工具链——开放的、多物理场的、3D原生的——是未来十年最重要的单一使能投资。
晶圆间工艺变异。 LogicFolding键合来自可能不同批次——在某些情况下不同节点——的晶圆。Vth、驱动电流和互连RC的晶圆间变异实质上大于晶圆内变异,且最严重地影响时钟分配和保持时间裕量。智能冗余、自适应补偿和τ感知的签核流程是必要的应对组件。
垂直互连开销。 每个混合键合和每个TSV都产生有限的电阻和电容惩罚,TSV KOZ排挤标准单元。因此LogicFolding必须逐层通过简单不等式来证明其合理性:
τBenefit(有效硅面积 + 线长缩减)> τPenalty(垂直互连RC)
这一阈值已在移动关键路径和存储器上被跨越;阈值是工作负载特定的,边界将随键合间距缩小而移动。
能量。 τ是时间定律,不是焦耳定律。一个运行快10倍但功耗大10倍的超级节点不违反任何缩放原则,但超出电网容量。因此τ缩放需要一个能量伴侣:消除堆栈开销的存储语义互联架构、将每比特皮焦耳降低数量级的近/共封装光学、背面供电、存内/近存计算,以及将τ余量换回功耗的纪律性实践(数据中心规模的DVFS——与使智能手机电池续航成为可能的机制相同)。重要的是,τ余量本身在朝该方向分配时提供能量余量。
基准测试。 行业当前的性能基准——Linpack、MLPerf、SPEC——是为每个工作负载一个标量即可满足的时代设计的。τ缩放行业需要τ剖面基准——暴露系统每一层主导τ及该层剩余余量的向量。主导τ层按定义就是下一个投资方向。
7. 六年回顾,十年展望
2020年5月至2026年5月间,华为半导体设计并量产了381颗芯片,服务于移动、AI、汽车、工业和基础设施市场。在该产品组合中,τ缩放论点经受住了考验:
- 在器件和电路层,晶体管密度已从155向2031年的400+ MTr/mm²发展。
- 在芯片层,LogicFolding已在前沿移动SoC上证明,关键路径频率、能效和密度可以在固定器件节点上继续推进。
- 在系统层,Unified Bus和Hi-ONE已证明数百微秒的通信τ可以被压缩到数百纳秒,多机架AI集群可以表现为单一一致机器。
- 展望未来,CPU性能核心频率预计到2029年达到4 GHz及以上,麒麟SoC效率预计在三到五年内在典型使用下翻倍以上,AI硬件集成预计到2035年增长超过100倍。
更深层的主张超越任何单一产品,是方法论层面的。τ缩放是自Dennard以来第一个给予整个堆栈共享优化目标的缩放原则。它向工艺技术专家、电路设计师、架构师、系统工程师和软件团队发出信号:这些社区现在正在用相同的单位优化同一个量,任何单一层的改进必须传播到系统τ才算数。它还向行业战略家和资本配置者表明,下一美元应该跟随τ而非节点——竞争性能不再需要永久驻留在光刻的最前沿,封装、存储带宽和互联架构设计现在拥有此前仅由前沿逻辑节点独占的战略权重。
对于受教育将"摩尔定律"等同于"进步"的一代工程师而言,这是一个困难的转变。几何时代事实上已经结束;否认这一事实不是可行的策略。通过微型化加速的时代正在让位于通过多层电子系统τ优化加速的时代——在未来六到十年内采纳τ作为首要目标的公司、研究团体和生态系统将决定此后十年计算的形态。
未来十年的工作范围已确定。许多开放问题仍然存在,没有任何单一组织能独自解决——工具链、标准、基准测试、器件物理和经济模型都需要超越任何一家公司的贡献。因此,本文既是来自前线的报告,也是一份邀请。
前方的路线图要求严苛,但方向是明确的。
作者
何庭波领导华为的半导体业务。她所领导的团队在2020年至2026年间设计并量产了381颗芯片,覆盖移动、AI、汽车和基础设施市场,是τ缩放方法论以及本文所述LogicFolding、Unified Bus和Hi-ONE技术的来源。
致谢
本文基于华为半导体及其代工、设备、EDA和系统合作伙伴生态系统中数千名工程师六年的工作。作者感谢那些以耐心使这项工作成为可能的客户。
延伸阅读
- G. E. Moore, "Cramming more components onto integrated circuits," Electronics, vol. 38, no. 8, pp. 114–117, Apr. 1965.
- R. H. Dennard et al., "Design of ion-implanted MOSFETs with very small physical dimensions," IEEE J. Solid-State Circuits, vol. 9, no. 5, pp. 256–268, 1974.
- J. L. Hennessy and D. A. Patterson, "A new golden age for computer architecture," Commun. ACM, vol. 62, no. 2, pp. 48–60, Feb. 2019.
- M. Horowitz, "Computing's energy problem (and what we can do about it)," ISSCC Dig. Tech. Papers, pp. 10–14, Feb. 2014.
- International Roadmap for Devices and Systems (IRDS) — Interconnect and More-than-Moore chapters, 2023/2024 update.
- P. Batude et al., "3D sequential integration: a key enabling technology for heterogeneous co-integration of new functions with CMOS," IEEE J. Electron Devices Soc., vol. 3, no. 3, pp. 205–216, 2015.
本文为 华为论文 A Time Scaling Theory for Multi-Layer Electronic Systems翻译稿|得中书局@szslg 免责声明: 本文为个人学习用途的翻译笔记,原内容版权归原作者]所有。译文力求还原原意,但受限于个人水平,可能存在理解偏差或表述不当,内容仅供参考翻译,不代表本人立场。Disclaimer: This post is a personal translation for educational purposes. All copyrights belong to the original creator . While I strive for accuracy, potential nuances or errors may exist. This content is for reference only and does not represent my personal views.